枯燥而丰富的 CSAPP 学习生活结束了。
第四章: 存储器层次结构
在简单的模型中,我们将存储器视作一个线性数组,CPU 可以在常熟世间内访问每个存储器的位置。但实际上,存储器系统是一个 具有不同容量、成本和访问时间 的设备层次结构,这都基于一个称作 局部性 的基本属性,使得该层次结构可以得到最优实现。
一。局部性
局部性指一个程序倾向于引用 临近于最近引用过的数据项 的数据项。局部性分为时间局部性和空间局部性。在 时间局部性 中,被引用过一次的内存位置在不久的将来会被多次引用;在 空间局部性 中,若一个内存被引用一次,那么程序在不久的将来会引用附件的内存位置。
对于以下的代码片段:
int sumv(int *v)
{
int i, sum = 0;
for (int i=0; i<n; i++) sum += v[i];
return sum;
}
该程序片段具有良好的空间局部性,因为它每次顺序访问数组中下一个元素,我们称其具有 步长为 1 的引用模式。若将 i++ 改为 i+=k,我们称作 “步长为 k”。随着步长增加,空间局部性下降。
对于二维嵌套数组,如果按照行优先顺序读元素的话能具有良好的空间局部性,但按照列顺序扫描的话会导致其步长为 N,使得程序效率降低。
二。缓存
一般而言,缓存 是一个小而快速的存储设备,作为更大更慢的存储设备中数据对象的缓冲区。存储器层次结构的核心思想 是,对于每一个 k,位于 k 层的更快更小的存储设备作为位于 k+1 层存储设备的缓存。
我们将第 k+1 层的存储器划分为一个个连续的数据对象组,称为 块。每个块有唯一的地址,且大小固定(通常)。第 k 层的缓存始终包含下一层 块的一个子集 的副本,且数据总是以块为最小单位进行复制传送的。L1 和 L0 之间的传送 通常使用的是 1 个字大小的块。L2 和 L1 之间(以及 L3 和 L2 之间、L4 和 L3 之间)的传送通常使用的是几十个字节的块。
当第 k+1 层的数据对象 d 可以在 k 层缓存中查找到,我们称其为 缓存命中。否则称为 缓存不命中,此时我们将 k+1 层中的数据 d 一个副本存在 k 层缓存中。如果 k 层缓存是满的,我们可能会覆盖一个块,被替换的这个块称为 牺牲块;如果此时 k 层缓存是空的,那任何数据对象都不会命中,我们称其为 冷不命中。
三。通用结构
考虑一个计算机系统,其存储器地址有 m 位,共有 个不同的地址;其中高速缓存被组织为一个 个缓存组的数组,而每个组包含 E 个缓存行,每个行又是由 字节的数据块组成(草什么套娃);
每行开头有一个有效位,告诉我们这行是否包含有意义的信息,还有 t=m-b-s 个标记位,唯一标识组中的一个行。
对于一个地址,参数 s, b 将其分为了三个字段,s 位组索引告诉我们这个字存储在哪一个组中;t 位标记位和每组的标记匹配,告诉我们组中哪一行包含这个字;b 位块偏移给出了数据在 B 字节中的位置。
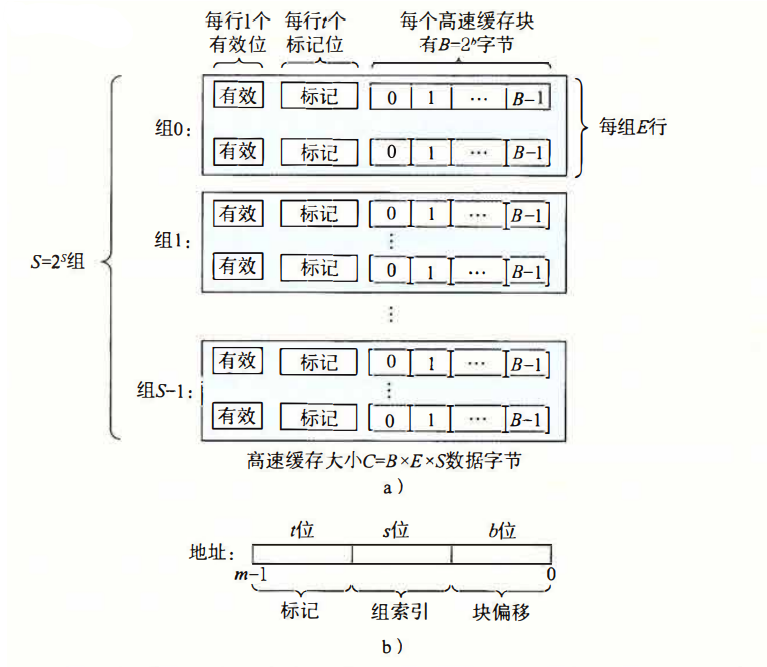
当 CPU 执行一条读取内存字 w 的指令时,他会向 L1 缓存请求这个字,这分为三步走:
- 组选择:根据组索引位确定在哪个组;
- 行匹配:若该组 有效位设置,且 组标记位和地址中的标记位相同,则块偏移选择起始字节;若一个组有多行,则需要逐一检查。
- 字选择:把块看成一个数组,直接加上偏移量即可。
- 行替换:若缓存不命中,从下一层取出被请求的块并替换一个现存行。
对于一个组只有一行的 直接映射高速缓存(即 E=1),直接替换当前行即可;对于 组相联高速缓存,我们有更多策略,其中常用的是 LFU (Least-Frequently-Used) 策略,替换在过去某个时间窗口内 引用次数最少 的那一行;LRU (Least-Recently-Used) 策略,替换最后一次 访问时间最久远 的那一行。
直接映射高速缓存模型简单,但却容易出现冲突不命中的问题(详细可见书 P431)。因为我们在 x 和 y 的块之间 抖动(thrash)。术语 “抖动” 描述的是,缓存反复地加载和驱逐含有相同的高速缓存块的组的情况。
此外,还有关于 写 的问题,懒得抄了:

通常,我们采用 写回 和 写分配 的缓存模型,因为其利用了良好的局部性。
第六章: 虚拟内存
开始的系统中,各个进程共享 CPU 和主存资源。然而随着进程数量增多,内存可能会不够用,且容易发生冲突。为了 更有效地管理内存,现代系统提出了对主存的 抽象,叫做虚拟内存(VM)。
一。内存作为缓存的工具
概念上,虚拟内存是一个 存放于磁盘上,N个连续的字节大小的单元 组成的数组。每个字节有唯一的虚拟地址,作为到数组的索引,该数组的内容被缓存在主存中。虚拟内存的数据被划分为一个个固定大小的 虚拟页(VP)。任意时刻,虚拟页面包含以下板块:
- 未分配的 :VM 系统为分配地址到该页,没有数据与其关联,不占用磁盘空间;
- 缓存的 :当前已缓存于物理内存中的已分配页;
- 未缓存的 :未缓存在物理内存上的已分配页。
虚拟内存系统必须有某种方法,来 判定一个虚拟页是否缓存在 DRAM 中的某个地方。系统还必须确定已缓存的虚拟页 存放在哪个物理页中。如果不命中,系统必须判断这个虚拟页 存在磁盘的哪个位置,在物理内存中选择一个牺牲页,并将虚拟页从磁盘复制到 DRAM 中,替换这个牺牲页。
操作系统,MMU(内存管理单元)的地址翻译软件和存放在物理内存中的 页表 共同实现了这些功能。页表实现了虚拟页到物理页的映射,其实质上是包含了一个页表条目(PTE)的数组。
我们假设每个 PTE 是由一个有效位和一个 n 位地址字段组成的。有效位表明了该虚拟页是否被缓存;若设置了有效位,则地址字段表示了 DRAM 中相应物理页的起始位置。若没有设置有效位,地址将指向该虚拟页 在磁盘上的起始位置。
当 CPU 成功读取一个被缓存于 DRAM 的虚拟页时,我们称其页命中;否则称其为缺页,发生缺页会触发缺页异常:内核从磁盘复制对应的虚拟页到内存中,并选择某个牺牲页而取代他。结束异处理程序后会重新进行该指令,此刻没有了异常。
在磁盘和内存之间传送页的活动叫做 页面调度。直到最后时刻,也就是当有不命中发生时,才换入页面的这种策略称为 按需页面调度。借助这种调度手段以及我们常见的 局部性原理,程序趋向于在一个较小的工作集中工作,程序开始时我们将工作集页面调度到内存,便可保证较少的缺页情况,减少不命中开销。
二。虚拟内存作为内存保护的工具
任何现代计算机系统必须为操作系统提供手段来控制对内存系统的访问。就像我们所看到的,提供独立的地址空间使得区分不同进程的私有内存变得容易。而且每次 CPU 生成一个地址时,地址翻译硬件都会读一个 PTE,所以通过 在 PTE 上添加一些额外的许可位来控制对一个虚拟页面内容的访问十分简单。
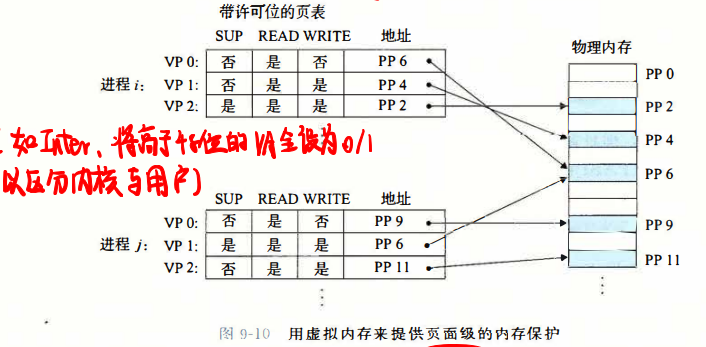
如果一条指令违反了这些许可条件,那么 CPU 就触发一个一般保护故障,将控制传递给一个内核中的异常处理程序。Linux 一般将这种异常报告为 段错误。
三。虚拟地址及翻译
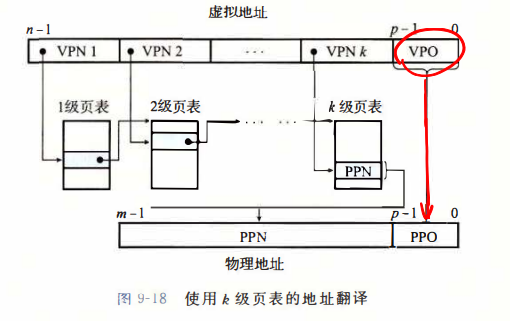
CPU 通过生成虚拟地址访问主存,这个虚拟地址在被送到内存之前先转换为适当的物理地址。将虚拟地址转化为物理地址的任务叫做 地址翻译。CPU 上的内存管理单元(MMU)利用存放在主存中的页表来 动态翻译虚拟地址。
CPU 首先将页表基址寄存器(PTBR)指向当前页表。一个 n 位的虚拟地址包含两部分:p 位的虚拟页面偏移和一个 n-p 的虚拟页号。MMU 利用虚拟页号(VPN)选择适当的 PTE,将其页表条目中的物理页号(PPN)和虚拟地址的后 p 位偏移量串联,就得到了对应的物理地址。
- 基本结构
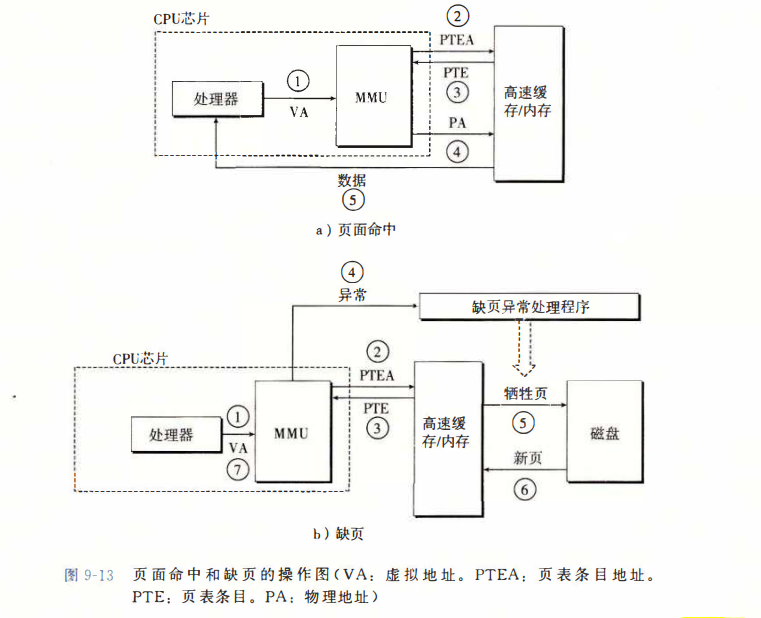
CPU硬件执行的步骤大致如下:
- 笫l步: 处理器生成一个虚拟地址,并把它传送给 MMU。
- 笫2步: MMU生成 PTE 地址,并从高速缓存/主存发送请求。
- 笫3步: 高速缓存/主存向 MMU 返回PTE。
- 笫4步: MMU 构造物理地址,并把它传送给高速缓存/主存。
- 笫5步: 高速缓存/主存返回所请求的数据字给处理器
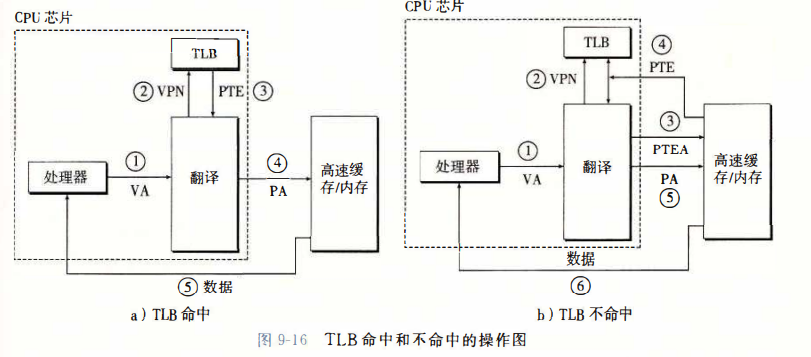
- TLB 加速
如果每次查阅 PTE 都可以在 L1 中,那开销大约是1~2周期,但我们连这个也可以省去。显然的是,页表条目也可以缓存,MMU 包括了一个关于 PTE 的小缓存,称为翻译后备缓冲器(TLB)。当 CPU 产生虚拟地址后,MMU 从 TLB 取出对应的 PTE(这发送在 CPU 中所以很快)。
当发生TLB 不命中时,MMU 必须从 L1 缓存中取出 PTE,将其存放于 TLB 中。
- 多级页表
对于较大的虚拟空间来说,一个单独的页表可能会十分庞大(48位地址可达到 GB 量级),这还没算上其中大量的虚拟地址不会被访问到。
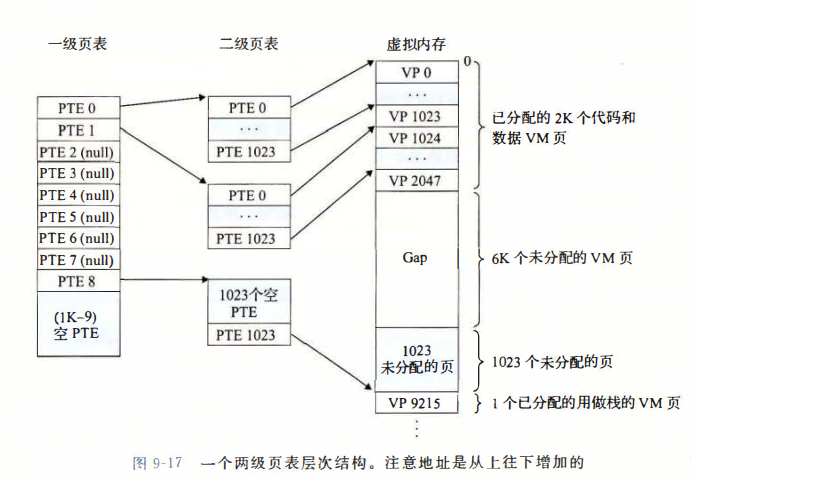
我们使用 多级页表 的方法对其进行压缩,这里以二级为例。一级页表中的每个 PTE 映射了虚拟空间中一个 4MB 的片段,一个片段由 1024 个连续的页面组成。若片 i 的每个页面都未被分配,则片段 i 为空,否则一级 PTE 将指向一个二级页表的基址;二级页表映射了 4KB 的虚拟内存页面,每一个 PTE 对应了虚拟空间中一个 4 字节的内存。
这种方法从两个方面减少了内存要求。
-
第一, 如果一级页表中的一个 PTE 是空的,那么相应的二级页表就根本不会存在。
-
第二, 只有一级页表才需要总是在主存中,虚拟内存系统可以在需要时创建、页面调入或调出二级页表,减少了主存的压力;